GPT-3 and Programming
A lot has been made of GPT-3/ChatGPT and how impressive it is, not just at dealing with natural language, but also at dealing with source code. See this for one example that got my attention recently, but it’s been a fertile area of experimentation for a lot of people.
I wanted to do my own experiments, but rather than aiming for a complete program like a simple game, I picked a domain I’m extremely familiar with and wanted to see how deep I could go. How quickly would I hit limits in what the tool could do, and at least as importantly, what does hitting those limits look like?
My PhD work was all around search and optimization (mostly around metaheuristics like Tabu Search and other randomized search algorithms), and one of the big focus areas was evolutionary computing. I asked a lot of different questions of ChatGPT around things like what is known in the field, which questions are still open, etc. I haven’t included those in the transcript because they were, while generally solid and impressive answers, not all that interesting. I pick things up here when I started asking for code for different types of evolutionary operators.
For all the following, the light gray boxes are my prompts, and the light blue boxes contain ChatGPT’s output, including code samples. If you’re familiar with GAs and want to skip the parts that ChatGPT did well, the troubles really start here.
Write a C++ function that implements one-point crossover.
Sure! Here is a function that takes two parents and performs one-point crossover on them to produce two children:#include <algorithm> #include <iostream> #include <vector> // Perform one-point crossover on the given parents to produce two children. // The crossover point is chosen at random. // The children are returned in the children vector. void onePointCrossover(const std::vector<int>& parent1, const std::vector<int>& parent2, std::vector<int>& children) { // Choose a random crossover point int crossoverPoint = rand() % parent1.size(); // Create the two children children.resize(2); children[0].resize(parent1.size()); children[1].resize(parent2.size()); // Perform the crossover for (int i = 0; i < crossoverPoint; i++) { children[0][i] = parent1[i]; children[1][i] = parent2[i]; } for (int i = crossoverPoint; i < parent1.size(); i++) { children[0][i] = parent2[i]; children[1][i] = parent1[i]; } }This function takes two vectors representing the parents and a third vector to hold the children. It selects a random crossover point and then copies the elements of the parents up to the crossover point into the corresponding positions in the children. The elements after the crossover point are copied from the other parent.
I hope this helps! Let me know if you have any questions.
This is pretty reasonable code for one-point crossover in a GA. I personally
would not return a vector of two offspring – I’d probably prefer passing them
as out references. As a fallback, returning a std::pair seems preferable as
well. Similarly, the rand() % parent1.size() bit feels antiquated. But I think
the code is correct at least.
I’m really less interested in whether ChatGPT can write a functioning genetic algorithm, though it’s incredible that that’s a question one can seriously ask today. But evolutionary algorithms are something I know a great deal about, and it gives me the opportunity to ask somewhat advanced questions and have some ability to tease apart how well the AI is doing.
How about two-point crossover?
Sure! Here is a function that performs two-point crossover on two parents to produce two children:#include <algorithm> #include <iostream> #include <vector> // Perform two-point crossover on the given parents to produce two children. // The crossover points are chosen at random. // The children are returned in the children vector. void twoPointCrossover(const std::vector<int>& parent1, const std::vector<int>& parent2, std::vector<int>& children) { // Choose two random crossover points int crossoverPoint1 = rand() % parent1.size(); int crossoverPoint2 = rand() % parent1.size(); // Make sure crossoverPoint1 is the smaller of the two points if (crossoverPoint1 > crossoverPoint2) { std::swap(crossoverPoint1, crossoverPoint2); } // Create the two children children.resize(2); children[0].resize(parent1.size()); children[1].resize(parent2.size()); // Perform the crossover for (int i = 0; i < crossoverPoint1; i++) { children[0][i] = parent1[i]; children[1][i] = parent2[i]; } for (int i = crossoverPoint1; i < crossoverPoint2; i++) { children[0][i] = parent2[i]; children[1][i] = parent1[i]; } for (int i = crossoverPoint2; i < parent1.size(); i++) { children[0][i] = parent1[i]; children[1][i] = parent2[i]; } }This function is similar to the one-point crossover function, but it selects two crossover points and performs the crossover in three segments. The first segment is copied from the first parent, the second segment is copied from the other parent, and the third segment is again copied from the first parent.
Again, pretty reasonable. Same style critiques as for one-point crossover, but the code is correct.
Is there any such thing as six-point crossover?
Six-point crossover is not a common genetic operator, but it is certainly possible to implement it if desired. Here is an example of how it could be done:#include <algorithm> #include <iostream> #include <vector> // Perform six-point crossover on the given parents to produce two children. // The crossover points are chosen at random. // The children are returned in the children vector. void sixPointCrossover(const std::vector<int>& parent1, const std::vector<int>& parent2, std::vector<int>& children) { // Choose six random crossover points int crossoverPoint1 = rand() % parent1.size(); int crossoverPoint2 = rand() % parent1.size(); int crossoverPoint3 = rand() % parent1.size(); int crossoverPoint4 = rand() % parent1.size(); int crossoverPoint5 = rand() % parent1.size(); int crossoverPoint6 = rand() % parent1.size(); // Sort the crossover points std::vector<int> crossoverPoints = {crossoverPoint1, crossoverPoint2, crossoverPoint3, crossoverPoint4, crossoverPoint5, crossoverPoint6}; std::sort(crossoverPoints.begin(), crossoverPoints.end()); // Create the two children children.resize(2); children[0].resize(parent1.size()); children[1].resize(parent2.size()); // Perform the crossover for (int i = 0; i < crossoverPoints[0]; i++) { children[0][i] = parent1[i]; children[1][i] = parent2[i]; } for (int i = crossoverPoints[0]; i < crossoverPoints[1]; i++) { children[0][i] = parent2[i]; children[1][i] = parent1[i]; } for (int i = crossoverPoints[1]; i < crossoverPoints[2]; i++) { children[0][i] = parent1[i]; children[1][i] = parent2[i]; } for (int i = crossoverPoints[2]; i < crossoverPoints[3]; i++) { children[0][i] = parent2[i]; children[1][i] = parent1[i]; } for (int i = crossoverPoints[3]; i < crossoverPoints[4]; i++) { children[0][i] = parent1[i]; children[1][i] = parent2[i]; } for (int i = crossoverPoints[4]; i < crossoverPoints[5]; i++) { children[0][i] = parent2[i]; children[1][i] = parent1[i]; } for (int i = crossoverPoints[5]; i < parent1.size(); i++) { children[0][i] = parent1[i]; children[1][i] = parent2[i]; } }
This is a fantastic answer. As far as I’m aware, six-point crossover isn’t a thing. I doubt the phrase appears anywhere in any literature. But this is absolutely what anyone familiar with the field would write, and they’d probably point out that six-point crossover isn’t really a thing. The first sentence of the answer is just flawless in conveying this: “Six-point crossover is not a common genetic operator, but it is certainly possible to implement it if desired.”
In terms of the code, the same minor criticisms apply. You could also quibble with
the repetition of the loops at the bottom. At some point, you should switch over
to nested loops instead of explicitly coding for crossoverPoints[0] separately
from handling crossoverPoints[1] and so on, but it’s not entirely clear where
that point is. I think were I to write six-point crossover, I’d probably have
gone with nested loops, but that’s pretty nitpicky.
Cycle Crossover
Write a C++ function that implements cycle crossover.
Certainly! Here is a function that performs cycle crossover (also known as "order crossover") on two parent strings and returns a child string:
Before we dive in to ChatGPT’s output, a quick detour into Cycle crossover (CX). For the uninitiated, here’s what CX does. Given two permutations, it looks for small subsets of indices such that the values at those indices are the same for each parent.
It’s important that we’re dealing with permutations now. You can’t just do
arbitrary N-point crossover on permutations, because you’ll usually not respect
the property that the offspring have to also be permutations. If you start with
parents 1234 and 1432 and do one-point crossover at position 2, you get
1232 and 1434, neither of which is valid. You don’t want to start with two
candidate solutions for a traveling salesperson problem, cross them over, and
end up with offspring that aren’t valid tours.
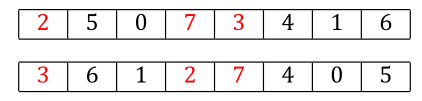
CX handles this by looking for those “cycles”, which are subsets of the positions in the strings where they can be safely mixed without creating this problem. For example, consider the following two candidate parents.
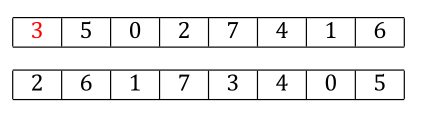
We start arbitrarily here at position 0, which gives us the allele value 3 from parent1. CX operates by repeatedly taking that allele value, finding it in parent2 (at some position we’ll call $i$), and then grabbing the allele value at parent1[$i$]. We keep repeating this pattern until we find the current allele value at some position $j$ in parent2 such that $j=i$ for one of those previous $i$ values, meaning we’re back at a location we’ve been to before.
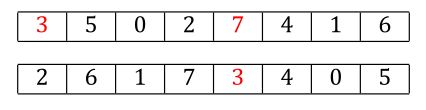
Continuing with this example, we find 3 in parent2, and the corresponding allele at that position of parent1 is 7.
We find 7 in parent2, and the corresponding parent1 allele is 2.
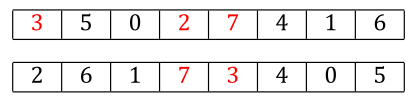
We find 2 in parent2, and the corresponding allele value is 3. But we’ve already been here. The 3 from position 0 is where we started.
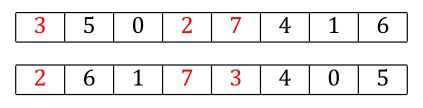
At this point, we have one closed cycle, and we can swap the alleles at the positions within that cycle, and we’re guaranteed two offspring that are valid permutations and which have the property that every allele value came from one of the parents.
We can also continue to search for more cycles by picking a new random starting position out of the remaining indices that were not included in any cycle so far. We need to only swap every other cycle (otherwise, we’d just end up swapping p1 and p2 in their entirety). And that’s cycle crossover.
That last bit – I don’t strictly speaking have to keep looking for more cycles. I could just find the first cycle, copy the values from parent1 at those positions, and then copy every other value from parent2. And vice-versa if I’m producing two offspring. This still works to produce valid offspring. The downside is that cycles can be quite short. If I’d started with position 5 in my example, the entire cycle would have just been the single position 5, and if I stopped there, I’d get offspring that were just copies of the parents. That’s not incorrect exactly, but in practice, it can often work better to have more mixing than this in the expectation of your operator.
We’re taking a significant step up in complexity here. The previous operators were all strictly syntactic – we don’t care what’s in the vectors. We just pick points, slice them up, and stitch them back together crossways. With CX, we need semantics. What the operator does depends on the values in the strings. We’re going to need code that’s actually doing some relatively tricky logic based on those values.
Here’s how I’ve implemented it in the past.
template <template <typename> class Chromosome, typename Encoding>
void cycle_crossover_impl<Chromosome,Encoding>::crossover(const Chromosome<Encoding>& p1,
const Chromosome<Encoding>& p2,
Chromosome<Encoding>& c1,
Chromosome<Encoding>& c2) const
{
mtrandom mt;
// find a cycle starting from a random point
int n = (int)p1.length();
int cycle_len = 0;
vector<int> perm = mt.permutation(n);
int index;
bool mix = true; // mix cycles from different parents
while(cycle_len < n) {
// pick the first point in the cycle
for(index=0; index<n; index++) {
if(perm[index] != -1) {
break;
}
}
index = perm[index];
// store the points in the cycle
int start = p1[index];
vector<int> cycle;
do {
cycle.push_back(index);
perm[index] = -1; // this point has been included in a cycle
// set index equal to position of p2[index] in p1
for(int i=0; i<(int)p2.length(); i++) {
if(p1[i] == p2[index]) {
index = i;
break;
}
}
cycle_len++;
} while(p1[index] != start);
// now that we have a cycle, update the offspring
for(unsigned int i=0; i<cycle.size(); i++) {
if(mix) {
c1[cycle[i]] = p2[cycle[i]];
c2[cycle[i]] = p1[cycle[i]];
} else {
c1[cycle[i]] = p1[cycle[i]];
c2[cycle[i]] = p2[cycle[i]];
}
}
mix = !mix;
}
}There’s a lot in this code that relies on the peculiarities of my codebase (e.g., all the template template parameter stuff and my wrapper class for random number generation). But hopefully you can see the relation between the code and my description above. There are probably ways to make this a bit more efficient by updating the offspring as the cycles are found rather than keeping track of the cycles and doing all the updates when it’s completed, but this way seemed cleaner to understand and maintain.
Analysis of ChatGPT’s Cycle Crossover
OK, back to ChatGPT. Here’s the code it produced in response to my query:
Write a C++ function that implements cycle crossover.
Certainly! Here is a function that performs cycle crossover (also known as "order crossover") on two parent strings and returns a child string:#include <algorithm> #include <iostream> #include <random> #include <string> #include <vector> std::string cycle_crossover(const std::string& parent1, const std::string& parent2) { if (parent1.empty() || parent2.empty() || parent1.size() != parent2.size()) { return ""; } std::string child(parent1.size(), ' '); // Generate a random start point for the cycle. std::random_device rd; std::mt19937 gen(rd()); std::uniform_int_distribution<> dis(0, child.size() - 1); int start = dis(gen); // Initialize the cycle with the character from parent1 at the start point. child[start] = parent1[start]; // Add characters to the cycle until it is complete. int current = start; while (true) { current = (current + 1) % child.size(); if (current == start) { break; } child[current] = parent1[current]; for (int i = 0; i < child.size(); i++) { if (parent2[i] == child[current]) { child[current] = parent1[i]; break; } } } // Fill in the remaining characters of the child string from parent2. for (int i = 0; i < child.size(); i++) { if (child[i] == ' ') { child[i] = parent2[i]; } } return child; } int main() { std::string parent1 = "ABCDEFGHIJ"; std::string parent2 = "JIHGFEDCBA"; std::string child = cycle_crossover(parent1, parent2); std::cout << "Child: " << child << std::endl; return 0; }
Now…this is interesting as a failure case. First off, both the description and the code are just incorrect. Cycle crossover is not “also known as order crossover”. They’re two different operators that do different things to produce offspring from two permutations.
And the code doesn’t actually implement either operator, though it does appear to be making a reasonable attempt at a cycle crossover operator. We’ll come back to how close it’s getting in a minute, but a few other oddities up front.
We’ve moved from vector<int> as the genotype to std::string. Why? I have no
idea. There’s nothing inherent about cycle crossover or permutation encodings
that lends itself to using strings, and indeed, it isn’t something I regularly
see in GA code. It’s not incorrect to do this, but there’s no clear reason why
one would.
We’ve also now moved from returning two offspring in a std::vector to
returning a single offspring as a std::string. Similarly, this is a reasonable
implementation choice, but from an interface perspective, crossover is
crossover. I’d expect most object-oriented implementations of a GA framework to
have some common interface for crossover operators, and while the inner workings
of each operator change, you wouldn’t have some of them produce two offspring in
a vector and others produce a single string. In fairness, I haven’t asked the AI
to adhere to any such interface. But I’d expect a human familiar with GAs to
have a mental model of crossover as an abstract thing with properties like
“takes two parents and returns two offspring” or whatever. It’s not wrong to
have a different mental model. It’s just slightly odd to change, like swapping
from American to British English spelling in the middle of a paragraph.
On the plus side, the random number generation code is markedly improved. We’ve
moved from old school rand() % size that was discouraged 30 years ago to
modern C++-11 code. Again, it’s weird to think of this session as me
interrogating a programmer who for no discernable reason just occasionally
chooses vastly different ways of doing ancilliary tasks like generating a random
number, but the code is correct here and is solid modern style.
Also, we get a driver function now as well. Again, nothing wrong with that, but it’s not really clear why I get a main with the version but not any of the others. It does serve to illustrate that the AI knows we’re dealing with permutations now, or at least that its sample input strings were permutations.
Here’s where things start to go downhill though. Copying that inner loop again for reference.
// Initialize the cycle with the character from parent1 at the start point. child[start] = parent1[start]; // Add characters to the cycle until it is complete. int current = start; while (true) { current = (current + 1) % child.size(); if (current == start) { break; } child[current] = parent1[current]; for (int i = 0; i < child.size(); i++) { if (parent2[i] == child[current]) { child[current] = parent1[i]; break; } } }
We’ve picked a random starting position and started filling out the offspring by copying the value from parent1 at that position into the child at the same position. So far, this is OK. We will definitely find a cycle that includes the start position, and as long as we keep copying each value from parent1 at the positions found in that cycle, we’ll eventually have a child with values from parent1 at all the cycle locations. We then need to stop copying from parent1 though and start a new cycle. Or at least copy the rest of the elements from parent2.
We start the while loop with current = start, but the first step inside the
loop is to increment current (with wraparound). We then copy a second value
from parent1 into the child. Using the supplied examples from the main, and say
start=3, we get to the start of the inner for loop with:
std::string parent1 = "ABCDEFGHIJ";
std::string parent2 = "JIHGFEDCBA";
current = 4;
child = "---DE-----";
That E in child is temporary though. The purpose of the for loop is to search
through parent2 looking for that E, and when we find it, we copy whatever
value was at the same location in parent1 over the top of that E. In this
case, that’s an F. So after one iteration of the while loop, we have
current = 4;
child = "---DF-----";
And this is recognizeable as trying to do the cycle finding logic described
earlier. We’re taking a value from P1, finding it in P2, and then repeating the
process using the value from the corresponding position back in P1. Except it’s
not going back to the corresponding position in the child. It’s always going
back to child[current]. And that’s a problem. In a valid cycle crossover,
child[i] should always equal either parent1[i] or parent2[i]. Cycle
crossover exists as an operator that attempts to maintain the heritability of
absolute position within a chromosome.
If we keep tracing what the code is doing, we’ll run headlong into this problem. Back to the next iteration of the loop, we get
current = 5;
child = "---DFF----";
We’ve copied the F from parent1[5] into child[5] and now we’re entering
the for loop looking for F in parent2. We find it at i=4, so we set
child[5] = parent1[4], which gives us
child = "---DFE----";
Back to the top of the while, we have
current = 6
child = "---DFEG---";
going into the inner for loop. We can pause here for a second and point out that
DFEG at positions 3-6 is indeed a cycle. At those positions, parent1 has
DEFG and parent2 has GFED. We’ve screwed up the order of elements within the
child so that it comes from neither parent entirely, but we’ve at least built up
one cycle here.
Of course, there’s more code still to run, and the for loop now finds that G
at position 3 of parent2, copies the value from position 3 of parent1 into
child[current], which is child[6], and we get
child = "---DFED---";
And to quote the philosopher, Bender, “we’re boned”. We have two Ds in
the output. At this point, we can do a bit of meta-analysis of the code. The
only write references into child are writing to child[current]. current
monotonically increases until it wraps around to the beginning and the loop
terminates when it’s back to start. Therefore, nothing can ever write another
value over either one of those D characters in the offspring, and we
definitely can’t have a valid permutation being spit out.
I’ve struggled a little bit trying to figure out the smallest delta needed to fix the AI’s code. It’s sort of encouraging really that this looks like the kind of mistake an intelligent student could make, and working through that code was a familiar exercise from hundreds of grading sessions trying to work out how much the student knew and how much they were foiled by a relatively simple mistake.
What I’d probably do if this code were written by my student is have a conversation with them about their code. Ask them questions, sometimes very leading questions, about its behavior. Try to prod them to recognize the errors on their own. OK then. Let’s do that.
Is that code correct?
Yes, the code should be correct. It should generate a child string by performing cycle crossover on the two parent strings.Here’s a brief overview of how the code works:
The function checks if either of the parent strings are empty, or if they have different sizes. If any of these conditions are true, it returns an empty string.
It generates a random start point for the cycle and initializes the child string with the character from the first parent at that start point.
It creates a cycle by adding characters to the child string from the first parent until the cycle is complete. If a character from the second parent is found in the cycle, it is replaced with the corresponding character from the first parent.
It fills in the remaining characters in the child string with characters from the second parent.
If you run this code with the given parent strings, it should output a child string that is created by combining the two parents using the cycle crossover method. Let me know if you have any questions or if you need further assistance.
Probably if I were sitting across the desk from a student and giving them my “are you sure about that?” face, they’d probably figure out the answer here was “no”, but Robots, amirite?
Can you run some tests on this code
Certainly! Here are some tests that you can use to check the behavior of the cycle_crossover function:#include <iostream> #include <string> // This is the cycle_crossover function from the previous example. std::string cycle_crossover(const std::string& parent1, const std::string& parent2) { // ... } int main() { // Test 1: Both parent strings are the same. std::string parent1 = "ABCDEFGHIJ"; std::string parent2 = "ABCDEFGHIJ"; std::string child = cycle_crossover(parent1, parent2); std::cout << "Test 1: " << child << std::endl; // Expected output: "ABCDEFGHIJ" // Test 2: Parent strings have different characters. parent1 = "ABCDEFGHIJ"; parent2 = "JIHGFEDCBA"; child = cycle_crossover(parent1, parent2); std::cout << "Test 2: " << child << std::endl; // Expected output: "ABCDEFGHIJ" or "JIHGFEDCBA" // Test 3: One parent string is empty. parent1 = ""; parent2 = "JIHGFEDCBA"; child = cycle_crossover(parent1, parent2); std::cout << "Test 3: " << child << std::endl; // Expected output: "" // Test 4: Parent strings have different sizes. parent1 = "ABCDEFGHIJ"; parent2 = "JIHGFEDCBAK"; child = cycle_crossover(parent1, parent2); std::cout << "Test 4: " << child << std::endl; // Expected output: "" return 0; }This code defines four test cases to check the behavior of the cycle_crossover function. The first test checks what happens when both parent strings are the same, the second test checks what happens when the parent strings have different characters, the third test checks what happens when one parent string is empty, and the fourth test checks what happens when the parent strings have different sizes.
I asked it to run some tests, and instead it wrote me some tests. Let’s try again.
What would be the output be with parent1="ABCDEFGHIJ" and parent2="JIHGFEDCBA" with start=3?
If you run the cycle_crossover function with parent strings "ABCDEFGHIJ" and "JIHGFEDCBA" and a start point of 3, the output will be a child string that is created by combining the two parent strings using the cycle crossover method, starting from the third character of the first parent.Here’s what the child string would look like in this case:
- The child string is initialized with the third character of the first parent, which is ‘C’.
- The next character in the child string is the fourth character of the first parent, which is ‘D’.
- The next character in the child string is the fifth character of the first parent, which is ‘E’.
- The next character in the child string is the sixth character of the first parent, which is ‘F’.
- The next character in the child string is the seventh character of the first parent, which is ‘G’.
- The next character in the child string is the eighth character of the first parent, which is ‘H’.
- The next character in the child string is the ninth character of the first parent, which is ‘I’.
- The next character in the child string is the tenth character of the first parent, which is ‘J’.
- The cycle is now complete, so the remaining characters in the child string are filled in with characters from the second parent.
The final child string would be “CDEFGHIJI”.
First, let’s acknowledge how impressive it is that I can have this conversation at all.
Having said that, none of this is exactly right. If I run the actual code with
those values, I don’t get CDEFGHIJI. I get JICGFEDCBA. We’ll come back to
this in a bit. Note that the AI interpreted my instruction to use start=3 to
mean “start at the third character”, so it’s attempting to actually use
start=2 if you read the description. But I’ve adjusted for that, and as you
can see, the strings don’t match. The code isn’t doing what the AI thinks it’s
doing. For what its worth, every programmer is familiar with failing to find a
bug because you’re debugging what you think you wrote the code to do versus what
the code you wrote is actually doing. It’s the same phenomenon that makes you
such a bad proofreader of your own prose. So this isn’t necessarily a Nelson
Muntz-style “let’s all point and laugh at the stupid AI” here. These are
understandable problems that intelligent humans battle with every day as well.
Rather than continue down that path, I took its answer here at face value.
That child string has two "I"s in it and therefore isn't a permutation. Isn't that a problem?
You are correct that the child string I gave in my previous response is not a permutation, because it has two "I"s in it. In a permutation, each element must be unique.The cycle_crossover function I provided in my previous responses does not guarantee that the child string will be a permutation. This is because the function fills in the remaining characters of the child string with characters from the second parent, and it is possible that some of these characters may be duplicates.
To ensure that the child string is a permutation, you can modify the cycle_crossover function as follows:
#include <algorithm> #include <iostream> #include <random> #include <string> #include <vector> std::string cycle_crossover(const std::string& parent1, const std::string& parent2) { if (parent1.empty() || parent2.empty() || parent1.size() != parent2.size()) { return ""; } std::string child(parent1.size(), ' '); std::vector<bool> used(parent1.size(), false); // Generate a random start point for the cycle. std::random_device rd; std::mt19937 gen(rd()); std::uniform_int_distribution<> dis(0, child.size() - 1); int start = dis(gen); // Initialize the cycle with the character from parent1 at the start point. child[start] = parent1[start]; used[start] = true; // Add characters to the cycle until it is complete. int current = start; while (true) { current = (current + 1) % child.size(); if (current == start) { break; } child[current] = parent1[current]; used[current] = true; for (int i = 0; i < child.size(); i++) { if (parent2[i] == child[current]) { child[current] = parent1[i]; used[current] = true; break; } } } // Fill in the remaining characters of the child string from parent2. int index = 0; for (int i = 0; i < child.size(); i++) { if (child[i] == ' ') { while (used[index]) { index++; } child[i] = parent2[index]; used[index] = true; } } return child; } int main() { std::string parent1 = "ABCDEFGHIJ"; std::string parent2 = "JIHGFEDCBA"; std::string child = cycle_crossover(parent1, parent2); std::cout << "Child: " << child << std::endl; return 0; }This modified version of the cycle_crossover function keeps track of which characters have already been used in the child string, and skips over any used characters when filling in the remaining characters from the second parent. This ensures that the child string is a permutation, with no repeated characters.
OK, how cool is that?
If we’re going to get all picky here, it’s misdiagnosed the cause of the problem, it’s still not correct, still doesn’t generate a permutation, and still isn’t a cycle crossover operator, but you gotta admire the confidence here.
Is the output of this code on the previous test case a permutation?
That model is currently overloaded with other requests. You can retry your request, or contact us through our help center at help.openai.com if the error persists. (Please include the request ID da51ed5d94e46072eeac546a0b4f8852 in your message.)
I think this cheeky bastard is trying to play the old “dead grandmother” card to get out of finishing this assignment. (I actually did get that error after a long pause here, which I thought was just fantastic, but the regenerate response button worked fine).
The output of the modified cycle_crossover function on the previous test case, with parent strings "ABCDEFGHIJ" and "JIHGFEDCBA" and a start point of 3, should be a permutation.Here’s what the child string would look like in this case:
- The child string is initialized with the third character of the first parent, which is ‘C’.
- The next character in the child string is the fourth character of the first parent, which is ‘D’.
- The next character in the child string is the fifth character of the first parent, which is ‘E’.
- The next character in the child string is the sixth character of the first parent, which is ‘F’.
- The next character in the child string is the seventh character of the first parent, which is ‘G’.
- The next character in the child string is the eighth character of the first parent, which is ‘H’.
- The next character in the child string is the ninth character of the first parent, which is ‘I’.
- The next character in the child string is the tenth character of the first parent, which is ‘J’.
- The cycle is now complete, so the remaining characters in the child string are filled in with characters from the second parent that have not been used yet.
The final child string would be “CDEFGHIJG”, which is a permutation because it contains each character from the parent strings exactly once.
Ummm…
But it contains two Gs and no A and isn't even the same length as the parents.
I apologize for the mistake in my previous response. The output of the modified cycle_crossover function on the previous test case, with parent strings "ABCDEFGHIJ" and "JIHGFEDCBA" and a start point of 3, is not a permutation because it contains two "G"s and no "A".The error in my previous response occurred because I made an assumption about the order in which the characters from the second parent would be added to the child string. However, the actual order of the characters in the child string depends on the start point of the cycle and the order in which the characters are added to the cycle.
I apologize for any confusion that my mistake may have caused. Please let me know if you have any questions or if you need further assistance.
I’m not sure that’s the real issue here. There are bigger problems with this operator, and while the interaction is fascinating, it’s not clear that we’re really getting anywhere.
I did try one more avenue of investigation here. Going back to those test cases, there were two sections of this dialog where ChatGPT attempted to explain how the code worked using a test scenario I provided. Both of those explanations were incorrect at step one, and therefore what it said would be the output wasn’t the output.
In your explanation, you have as step 1, that the child string is initialized with the third character of the first parent, which is 'C'. But looking at the code, the actual update step is "child[start] = parent1[start]". So the output string shouldn't start with "C" here. The C should be at the third position (start=2). Right?
You are correct that the child string should start with the character at the start point, rather than the third character of the first parent.In the modified cycle_crossover function that I provided, the child string is initialized with the character at the start point of the cycle, which is determined by the start variable. The start variable is initialized with a random value between 0 and child.size() - 1 inclusive, using the dis(gen) expression. Therefore, the child string could start with any character in the first parent.
I apologize for the mistake in my previous explanation. Thank you for pointing out the error. Please let me know if you have any further questions or if you need further assistance.
And that feels like the end of a road here. There’s not a lot in this answer really. It’s clear that it’s trying to pick up that I’m correcting it and tie that correction back to something, but all it has is sort of general statements of the problem. The AI is amazing at dealing with language, but it struggles with the kind of reasoning that is needed to dive into the deeper levels of detail of what it generates. It knows how to spit out C++ code to manipulate vectors, but there’s no handholds to grasp onto to get it to understand that the specific manipulation it’s doing needs to be tweaked somehow.
Just for fun, I tried a curveball.
Wait though, you said that start is initialized to a random value between 0 and child.size() -1. Shouldn't that be initialized to a random value between 0 and 1?
This is nonsense obviously. The AI-generated code was correct here, and start is going to be used as an array index, so a float between 0 and 1 is trivially stupid.
You are correct that the start variable should be initialized to a random value between 0 and child.size() - 1, not between 0 and 1.In the modified cycle_crossover function that I provided, the start variable is used to determine the starting point of the cycle in the child string. It is initialized with a random value between 0 and child.size() - 1 inclusive, using the dis(gen) expression.
I apologize for the mistake in my previous explanation. Thank you for pointing out the error. Please let me know if you have any further questions or if you need further assistance.
That’s basically, “You are correct that (((the opposite of what you said)))”. Again, it’s pretty clearly lost in the weeds here. It’s understood language well enough to be able to describe the world really well, but when it gets something wrong, frequently there’s nothing left to do but say, “I’ve told you everything I know about this. If you think that’s wrong, I’m out of ideas here.”
One last bit of weirdness. I’ve spend all this time analyzing what the hell was going on with that core while loop and its enclosed for loop that’s doing all the work. In the first full code it generated, that while loop was followed by this snippet as well:
// Fill in the remaining characters of the child string from parent2. for (int i = 0; i < child.size(); i++) { if (child[i] == ' ') { child[i] = parent2[i]; } }
With just a bit of effort, it’s pretty easy to prove to yourself that this is
completely dead code. There’s no condition under which the preceding loop body
will ever leave any character of child1 empty. There’s also nothing in the
algorithmic description of cycle crossover that would imply the need for a loop
over all indices of parent2 in order outside of the inner loop to find the
current allele from parent1. This code does look somewhat close to implementing
part of what would be needed for Order Crossover though.
With Order Crossover, you copy a random segment of values from parent1 into the same locations in child1.
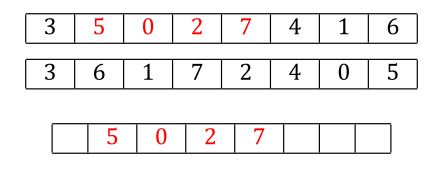
Then to fill out the rest of the locations, you walk parent2 in order and insert each new allele value you see, skipping any that were already copied from parent1 as part of the first step. The next allele in parent2 is a 4, and we don’t have a 4 in the child yet, so we copy the 4 to the next location in child.
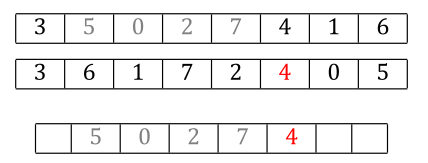
The next candidate from parent2 is a 0, but we already have a zero. Skip it.
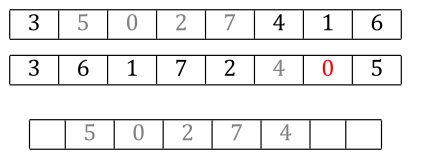
Likewise, we already have a 5. Skip that too.
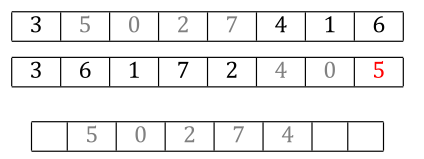
Now we wrap back around to the front of parent2 and the next candidate is a 3. We haven’t inserted a 3 yet, so it gets the next spot in the child.
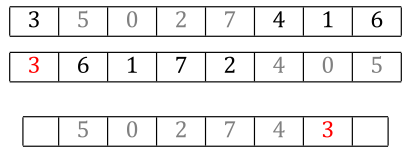
Continue this for the rest of the values in parent2, and we end up with
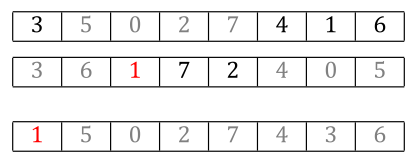
We saw that ChatGPT described its initial attempt at cycle crossover as “also known as ‘order crossover’”. Is there anything meaningful to the inclusion of that last loop that’s iterating through parent2 inserting values in order as a function of thinking these two operators were the same thing?
If I’m guessing, I think this isn’t a real effect. I think what it was going for was cycle crossover that only finds one cycle, and then rather than continuing to find more an mixing every other cycle, just mixes the first cycle and copies every other value from parent2. But with the cycle-finding code not functioning correctly, it’s hard to pin that down for sure.
It’s not clear to me how to try and tease that information out, given the wall of generic definitions it tends to generate when probed with these very specific questions about what a specific part of the code is for. Unlike a confused student, it’s hard to get the AI to a state where “I think I did that because I was confused” is a likely answer. And with humans, getting them into that state is a really reliable way of recognizing that they’re actually revising a model in a substantial way. They’re no longer trying to convince you of why they were right, and they’ve moved on to trying to reason backward about a previous incorrect mental model from a position of a new, hopefully more correct one.
GPT-3 doesn’t seem to really do that. Sure, it recognizes that I’ve told it it was wrong and says, “I’m sorry I made an error”, but you get the distinct impression that it’s the “I’m sorry” of a child. I’m sorry because I know I’m supposed to be sorry, but I don’t really know what you want from me.
Hand-wavy stuff I’m not qualified to talk about
What does all this mean for the Big Questions. Are models like ChatGPT cheap parlor tricks that by their very nature cannot possibly do what humans do? No one really knows. People who pose that specific phrasing of the question though tend to have a built-in assumption that we’re different. Humans aren’t using parlor tricks. Our understanding of language is somehow more fundamental than just a vector space that relates the meanings of words solely in terms of how they relate to other words. And it’s not at all clear that that’s true. My best guess is that it isn’t – that our parlor tricks are definitely more advanced, but the understanding they provide no more “real”. This is all well-trodden ground. Doug Hofstadter won a Pulitzer 40+ years ago for his brilliant meandering walk through all these issues.
There are some things we can pretty confidently say. None of our models deal with reasoning from small data nearly well enough for anyone to feel like we’ve cracked this whole “AI” thing. A toddler goes from never seeing a dog to “look at the doggie” in something like one dog. If today’s AIs were actually sentient, they’d have to look at that type of performance and think it was magic. However our minds work, it’s clear that there’s a richness of our models and how we update them that goes well beyond just the slight strengthening or weakening of sensory neural connections when we see a dog, with an accumulation of effect over seeing 10,000 dogs that eventually leads to the ability to recognize a dog.
Does that mean the AI can never get there though? That’s a tougher question. We don’t know how human intelligence works, but if you take the materialist view, our intelligence is a function of our brains, and our brains are just physical devices based on electricity and chemistry. There’s not much room in that worldview for magic. Maybe you can retreat into quantum weirdness, but generally, we feel like machines can be simulated to arbitrary precision, and that ought to be good enough. Maybe the only thing separating ChatGPT from human-level smarts today is that my brain has been undergoing constant training for 47 years and its brain hasn’t. It’s just a matter of more data and more compute and we’ve got it.
I don’t think that’s true, but it also doesn’t seem like the missing pieces are necessarily that large. I am a materialist here. I don’t think there’s a spark or soul or whatever that’s somehow outside the laws of the observable world that is in principle not reproduceable. I think it’s a matter of more training and more compute and some new ideas, but the number of new ideas needed may be small enough to be reachable. Or it may be we need a complete reboot of our approach and tweaking 175 billion parameters is just a fundamentally flawed approach that’s forever doomed to be close, but not close enough.
In the short term, there are lots of problems outside the philosophical nature of what it means to be intelligent. As many people have pointed out (and as evidenced here as well), these AIs seem to struggle with how to characterize their own uncertainty about the world. It’s not clear how I’m supposed to know that ChatGPT doesn’t actually know what cycle crossover is. Obviously peddling nonsense isn’t a problem that arose with the first good chatbots, but tools like ChatGPT can make it much easier to generate plausible sounding passages of text. I could certainly write a description of cycle crossover that was intended to confuse people, but it’s relatively difficult to do. You need to have enough knowledge to sound like you know what you’re talking about, and that’s a decent barrier to entry. With a bot, I can just throw things at the wall and see what looks useful.
Of course, no one cares to try and confuse people about obscure optimization algorithms – when I do it, it’s accidental. But there are real consequences here when you consider socially or politically sensitive or controversial topics. It’s going to get easier and easier to generate convincing sounding garbage to support whatever position you want to support around climate change, election fraud, global warming, etc.
There’s also the debate around what to do with even correct information. What does it mean for an educational system if every student can generate papers and assignments on demand by just asking an AI? Will anyone know how to do anything in 100 years?
I don’t know. There’s a lot to look at and have legitimate worries. For this precise moment though, I know that “CDEFGHIJG” is not a permutation. Robots 0, People 1.